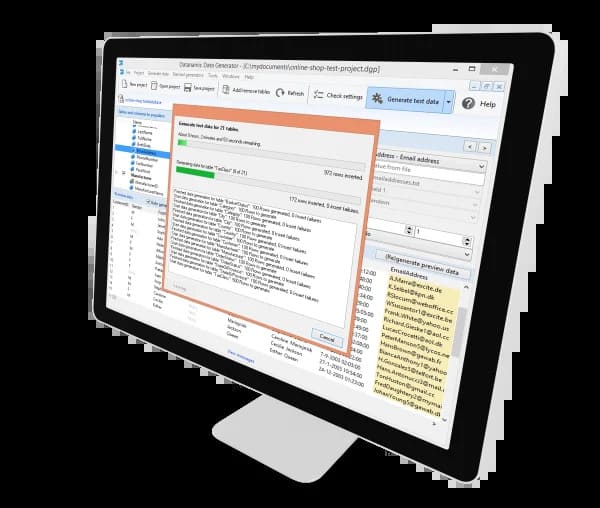
快速简介
需要快速为数据库填充真实感数据吗?Datanamic Data Generator。它非常适合开发人员、QA 团队以及任何需要数千条语法有效、遵循关联规则的测试记录的人,同时又不想使用生产数据。它为你节省大量时间,避免那些耗时且大量使用鼠标的手工数据录入工作。
程序能做什么
该工具附着于你的数据库模式,分析每张表的结构与约束,并生成抽样符合列类型与长度且遵守关系规则的行。支持最流行的关系型引擎,因此可为 Oracle、MySQL、MS SQL Server、PostgreSQL、SQLite 等生成数据。使用它你可以创建充斥着数百万相同记录的环境,其中包含重复或类键数据,而不是仅仅导出那些毫无意义的极端数据。
引擎如何工作
基本上它将数据集模板翻译成真实的列值。你可以选择最多三列,然后选择生成模式(如需要),它就会生成满足这些约束的数据。或者它也可以从现有数据表集中提取,用以生成父子关系数据并保持关系完整。应用内可将数据输出为 SQL 或 CSV 格式,并提供批处理模式以便一次填充数千或数百万行。关于连接与基于源的种子使用方法,请参阅产品文档或知识库,这能使对复杂模式的填充变得不那么困难。
主要功能
- 支持最流行的关系型数据库:Oracle、MySQL、Microsoft SQL Server、PostgreSQL、SQLite、InterBase 与 Firebird。
- 列感知生成器,可为文本、数值、日期/时间、GUID 等生成可接受的值。
- 能够遵守外键关系与唯一性约束,使生成的数据集仍然保持一致性。
- 面向营销使用的导出选项:INSERT 语句、SQL 脚本、CSV 输出,便于使用。
- 利用现有数据库条目作为生成条目的数据源或种子。为保持数据完整性与业务合理性,测试应从真实数据起步。
团队选择它的原因
你无需花费宝贵时间手工构建测试行。相反,你可以得到可重复的数据集,使你能够在真实环境条件下进行调试、负载测试和功能演示。开发人员会感激有代表性的数据集以复现缺陷。测试人员会高兴有遵循业务规则的数据,从而避免出现误报。运维人员可以在不担心破坏生产数据的情况下,配置可抛弃的数据库以进行性能测试。
- 这是安装程序,不是软件本体 – 更小、更快、更方便
- 一键安装 – 无需手动设置
- 安装程序将下载完整的 Datanamic Data Generator 2026。
安装方法
- 下载并解压 ZIP 文件
- 打开解压后的文件夹并运行安装程序
- 当 Windows 显示蓝色的“无法识别的应用”窗口时:
- 点击 更多信息 → 仍要运行
- 在用户账户控制提示中点击是
- 等待自动安装完成(约 1 分钟)
- 点击开始下载
- 下载完成后,从桌面快捷方式启动
- 开始使用
常见使用场景
为开发与 QA 环境填充符合约束的行,以反映类似生产的场景。
- 创建数百 GB 的数据以模拟查询、索引与备份/恢复过程的负载。
- 为演示和客户演示生成伪匿名数据集,当生产数据难以释放时使用。
- 快速填充 CI 流水线,以便自动化测试在多样且易复现的输入集上执行。
- 为培训、分析评估与 UI 原型创建示例数据集,便于保留必要的结构。
你会注意到的实用收益
你将获得速度。你将获得可重复性。你将获得遵守表规则的数据,因此测试总是以相同方式运行。开发团队减少了新项目的设置时间,因为他们可以让开发者团队将数据集创建脚本化为环境部署流程的一部分。并且你可以不断迭代:修改生成器、重新运行批处理,观察数据集如何适应你修订后的期望。这种敏捷性有助于保持开发周期运转,并消除生成测试数据时的长时间等待。
提示与行为说明
从适度开始。为那张关键表构建种子,然后向外扩展到所有相关表。约束是优势,不是障碍——让生成器利用约束来生成有效行。如果希望随机性可重现,请提供明确的种子或模板。并且总是在可抛弃的机器上先试验导出。
结语
如果你厌倦了脆弱的测试固件和隐藏真实问题的小型测试集,该生成器提供了实用的前进方式。它不是万能解,但能剔除数据准备中枯燥、乏味的部分,让你回到开发或测试上。尝试它、修改模板,很快就能找到保真度与速度之间的合适平衡。新版本会改进对目标平台与可用性的支持,因此在有新数据库时请查看变更日志。