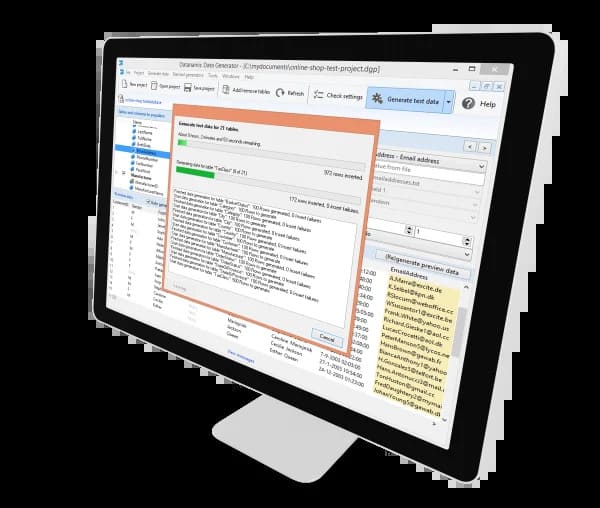
Introdução rápida
Precisa preencher seu banco de dados com dados realistas rapidamente? Datanamic Data Generator. É ideal para desenvolvedores, equipes de QA e praticamente qualquer pessoa que precise de milhares de registros de teste sintaticamente válidos e conscientes de relacionamentos, e que não queira mexer com dados de produção. Economiza muito tempo e evita a entrada manual de dados, que consome tempo e exige muitos cliques do mouse.
O que o programa faz
Esta utilidade conecta-se ao esquema do seu banco de dados, analisa a estrutura e as restrições de cada tabela e gera linhas que amostram os tipos e tamanhos de coluna e que seguem as regras dos seus relacionamentos. Suporta os motores relacionais mais populares para que você possa gerar para Oracle, MySQL, MS SQL Server, PostgreSQL, SQLite e similares. Usando-o você pode criar ambientes inchados com literalmente milhões de linhas idênticas com dados duplicados ou tipo chave, em vez de despejar dados radicais que não fazem sentido.
Como o motor opera
Basicamente traduz modelos para conjuntos de dados em colunas reais. Você seleciona até três colunas, depois um padrão gerador se desejar, e ele gerará dados que atendam essas restrições. Alternativamente pode puxar de um conjunto existente de tabelas para gerar dados pai/filho com as relações intactas. Ele exportará os dados em formato SQL ou CSV a partir da aplicação, e o modo em lote está disponível para popular milhares ou milhões de linhas de cada vez. A documentação sobre conexões e sementes baseadas em fonte pode ser encontrada na documentação do produto ou na base de conhecimento, o que pode tornar o seed de um esquema bastante complexo não tão difícil.
Principais recursos
- Suporte para os bancos de dados relacionais mais populares: Oracle, MySQL, Microsoft SQL Server, PostgreSQL, SQLite, InterBase e Firebird.
- Geradores que entendem a coluna e que geram valores aceitáveis para texto, numérico, data/hora, GUIDs etc.
- Capacidade de respeitar relações de chave estrangeira e restrições de unicidade para que o conjunto de dados gerado permaneça consistente.
- Opções de exportação voltadas a leads de marketing: instruções INSERT, scripts SQL e saída CSV para consumo confortável.
- Utilizar entradas existentes do banco de dados como fonte ou semente para gerar registros. Para preservar a integridade dos dados e o sentido de negócio, os testes devem partir de dados reais.
Por que equipes o escolhem
Você não terá que gastar horas valiosas construindo linhas de teste manualmente. Em vez disso, pode ter conjuntos de dados repetíveis que permitem depurar, testar carga e demonstrar funcionalidades em condições do mundo real. Desenvolvedores agradecerão por ter um conjunto representativo para reproduzir um bug. Testadores ficarão satisfeitos por ter dados que seguem regras de negócio para evitar falsos positivos. E a equipe de operações pode provisionar bancos de dados descartáveis para testes de desempenho sem se preocupar em corromper dados de produção.
- É o instalador, não o software em si – menor, mais rápido e conveniente
- Instalação com um clique – sem configuração manual
- O instalador baixa o Datanamic Data Generator 2026 completo.
Como instalar
- Baixe e extraia o arquivo ZIP
- Abra a pasta extraída e execute o arquivo de instalação
- Quando o Windows mostrar uma janela azul de “aplicativo não reconhecido”:
- Clique em Mais informações → Executar mesmo assim
- Clique em Sim no prompt de Controle de Conta de Usuário
- Aguarde a configuração automática (~1 minuto)
- Clique em Iniciar download
- Após o download terminar, inicie pelo atalho da área de trabalho
- Aproveite
Casos de uso comuns
Popular ambientes de dev e QA com linhas válidas segundo restrições para refletir cenários semelhantes à produção.
- Criar centenas de gigabytes de dados para simular carga em consultas, índices e backups/restores.
- Gerar conjuntos de dados pseudo/anonimizados para demos e apresentações a clientes onde é difícil liberar dados de produção.
- Popular rapidamente pipelines de CI para que testes automatizados sejam executados contra um conjunto diverso de entradas que é fácil de reproduzir.
- Para criação de conjuntos de dados de exemplo para treinamento, avaliação analítica e maquetes de UI onde a estrutura é necessária.
Benefícios práticos que você notará
Você terá velocidade. Você terá reprodutibilidade. Você terá dados que aderem às regras das tabelas para que seus testes sempre rodem de forma idêntica. Equipes de desenvolvimento reduzem o tempo de setup para novos projetos porque podem ter um time de desenvolvedores scriptando a criação do conjunto de dados como parte do processo de implantação do ambiente. E naturalmente você pode iterar: modifique seus geradores, execute novamente os lotes e veja como o conjunto de dados se adapta às suas expectativas revisadas. Essa agilidade ajuda a manter seus ciclos de desenvolvimento em movimento e elimina longas esperas para gerar dados de teste.
Dicas e notas de comportamento
Comece com um início moderado. Construa uma semente para sua tabela vital, depois expanda para todas as relacionadas. Restrições são uma força, não um impedimento – deixe o gerador usar restrições para gerar linhas válidas. Se quiser aleatoriedade reprodutível, informe sementes ou modelos explícitos. E sempre teste as exportações em uma máquina descartável primeiro.
Considerações finais
Se você está cansado de fixtures de teste frágeis e conjuntos de teste pequenos que escondem os problemas reais, este gerador oferece uma forma prática de avançar. Não é uma solução milagrosa, mas remove os aspectos chatos e tediosos da preparação de dados para que você possa voltar a desenvolver ou testar. Brinque com ele, modifique modelos e rapidamente encontrará o compromisso certo entre fidelidade e velocidade. Novas versões melhoram o suporte a alvos e a usabilidade, então verifique os logs de mudanças quando tiver um novo banco de dados.